【论文分享】大模型服务框架的缓存相关威胁分析
/ / 点击 / 阅读耗时 13 分钟在大模型(LLM)服务极速发展的当下,效率至关重要。为了降低延迟并控制算力成本,主流推理框架广泛引入了先进的缓存机制。然而,这种追求极致速度的设计是否埋下了安全隐患?
本论文是由奇安信技术研究院、中国海洋大学和清华大学联合完成的AI安全研究工作说明了缓存机制如果实现不恰当的话,就会造成安全隐患。论文题目为《Cache Me, Catch You: Cache Related Security Threats in LLM Serving Frameworks》。这项工作由中国海洋大学和奇安信联合培养的硕士研究生吴祥凡在奇安信技术研究院联培期间主导完成,导师为应凌云博士(奇安信星图实验室)和曲海鹏教授(中国海洋大学),其他作者为陈国强(奇安信星图实验室),谷雅聪(清华大学)。这项研究聚焦于大语言模型(LLM)推理服务框架中的安全威胁,深入分析了 KV Cache、多模态缓存及语义缓存 三大核心机制。

1. LLM推理加速背后的隐忧
随着模型参数规模的不断膨胀,推理计算的开销急剧上升。为了优化用户体验,vLLM、SGLang、GPTCache等主流服务框架引入了多种缓存策略,包括前缀缓存(Prefix Cache)、语义缓存(Semantic Cache)和多模态缓存(Multimodal Cache)。
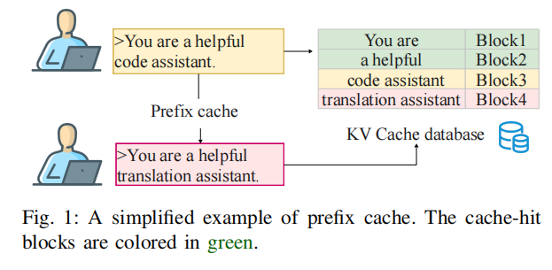
虽然这些机制通过存储中间状态极大地减少了重复计算,但我们的研究发现,现有的缓存实现往往“重效率、轻安全”。非加密哈希函数的滥用、有缺陷的对象序列化以及模糊的语义匹配标准,共同构成了一个全新的、尚未被充分探索的攻击面。与以往关注训练阶段的数据投毒不同,这是一类发生在推理阶段的全新安全威胁。
2. Cache Me, Catch You:首个LLM缓存安全系统性研究
为了揭示这一风险,我们对主流LLM服务框架的缓存实现进行了全面的解构与分析,并提出了六种新颖的攻击向量。这些攻击利用了哈希碰撞和语义模糊匹配的特性,能够在不接触模型权重的情况下,通过污染共享缓存来操纵模型输出。
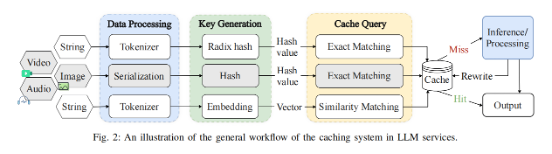
主要发现与攻击向量:
我们将发现的威胁归纳为两大类:一是面向用户的欺诈攻击,即攻击者利用系统渠道向用户传递恶意信息 ,具体手段包括利用哈希碰撞替换合法提示词以劫持对话逻辑的系统提示词碰撞、针对语义缓存构造高相似度恶意查询诱导错误回答的语义模糊投毒 ,以及在检索增强生成场景下利用文档相似性扩大攻击面的RAG语义投毒 ;二是系统完整性攻击,旨在破坏服务功能或绕过安全审查 ,具体涵盖构造与目标完整前缀碰撞以劫持响应的提示词碰撞劫持 、通过精心构造padding token让恶意代码块对LLM“隐形”以绕过审计的分块碰撞劫持 ,以及利用图像处理忽略元数据(如尺寸)缺陷构造哈希碰撞图片以绕过审核的多模态碰撞 。
细节详解:
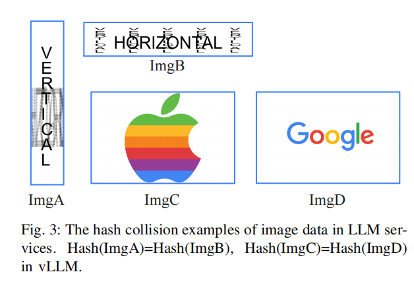
以多模态为例,其核心漏洞根源在于当前主流推理框架(如vLLM)在对多模态数据进行序列化时存在严重的逻辑缺陷。具体而言,vLLM默认调用PIL 的 tobytes() 方法来提取图像数据以计算哈希,该方法虽然能获取原始像素字节流,但在vLLM的后续操作中完全忽略了图像宽高等尺寸信息以及调色板等关键元数据。攻击者利用这一特性实施“尺寸伪装”攻击,通过重塑图像维度(例如将 H*W的图像变形为W*H)而不改变像素排列顺序,使得原本违规的图片变成一团毫无意义的噪点,从而生成与原图完全一致的哈希值。
此外,攻击者还能利用“调色板模式”漏洞,构造出索引数据相同但颜色定义截然相反的图片对(如黑底白字与白底黑字),由于序列化过程仅读取索引而忽略调色板定义,这两张视觉迥异的图片在系统眼中却拥有相同的“指纹”。

同样的隐患也出现在SGLang框架中,其为了适配张量数值范围将SHA256哈希值进行了取模截断,导致哈希空间被压缩至极易发生碰撞的范围。
下图是我们操纵图片当中的尺寸和PNG当中的P格式的调色盘,实现看上去不同的图片但是hash一致。
3. 实验效果与影响评估
我们在vLLM、SGLang及GPTCache等主流开源框架上进行了实测,证实了这些攻击路径的高可用性与低门槛:攻击者仅需不到1美元的成本即可完成一次投毒 。以针对vLLM的前缀缓存攻击为例,我们在30分钟内便成功搜索到碰撞哈希,实现了100%的缓存命中 。
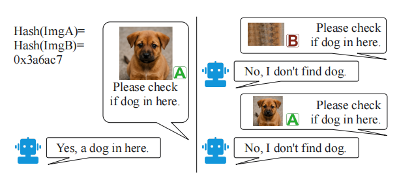
实验还还原了真实的威胁场景违规图片如何利用多模态缓存缺陷骗过内容审核系统。下图展示一个示意图,成功命中图片之后会复用之前的图片预处理结果,导致生成了错误回复。
4. 防御方案与行业响应
针对发现的漏洞,我们提出了五层防御策略,包括引入随机化哈希(Salting)、采用强加密哈希函数、强制规范化序列化流程、使用更鲁棒的Embedding模型以及增加LLM辅助过滤层。我们的理论分析和实际验证表明,上述的防御方案是可行的、有效的。
我们在第一时间将发现的漏洞通报给了受影响的厂商和社区,包括 vLLM、SGLang、GPTCache、AIBrix、rtp-llm 和 LMDeploy,并分配了 3个 CVE 编号。值得注意的是,vLLM、GPTCache 和 AIBrix 已经采纳了我们提出的缓解措施(如引入随机盐值、规范化图像序列化等)并完成了修复。(在本文发表时,SGLang也反馈采纳了我们的缓解措施。)
5. 讨论与未来展望
我们的研究再次表明,高性能不应成为忽视底层系统安全的理由。本研究证明,即便模型本身无懈可击,外围缓存框架的设计缺陷仍足以瓦解整个系统的信任基石;特别是在云端共享算力场景下,必须实施严格的多租户隔离与键值空间分离以防御跨租户攻击。作为填补推理侧缓存安全空白的先行工作,本研究旨在推动社区正视这一隐蔽威胁,共同构建更稳健的大模型服务基础设施。
更多参考
想了解更多技术细节?欢迎阅读我们的学术论文或访问项目主页:
代码仓库: https://github.com/XingTuLab/Cache_Me_Catch_You
感谢您的阅读,期待能为您的AI安全研究与工程实践带来启发!